NVIDIA lanza Nemotron-Labs-Diffusion: modelo con triple modo de decodificación
Por Redacción Automatización LatAm · 20 de mayo de 2026 · Fuente original: MarkTechPost
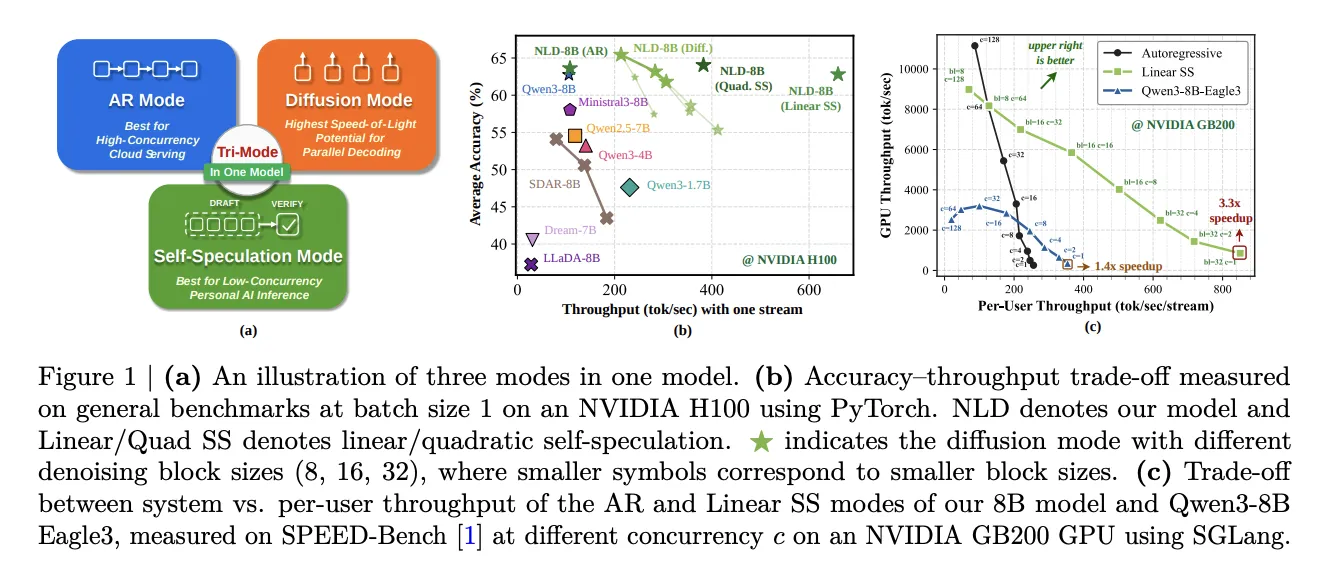
NVIDIA presentó Nemotron-Labs-Diffusion, una familia de modelos de lenguaje que integra tres modos de decodificación en una sola arquitectura. Disponible en variantes de 3B, 8B y 14B parámetros, alcanza 6× más tokens por paso que Qwen3-8B.
Arquitectura unificada de triple decodificación
NVIDIA ha presentado Nemotron-Labs-Diffusion, una familia de modelos de lenguaje que representa un avance importante en eficiencia de inferencia. A diferencia de las arquitecturas convencionales, este sistema integra tres estrategias de decodificación en un único modelo: decodificación autorregresiova (AR) clásica, decodificación basada en difusión en paralelo, y decodificación especulativa. Esta flexibilidad arquitectónica permite optimizar el throughput según el caso de uso específico.
Especificaciones y variantes disponibles
La familia Nemotron-Labs-Diffusion se ofrece en tres tamaños de parámetros: 3B, 8B y 14B, cubriendo un espectro desde dispositivos edge hasta servidores de inferencia de mayor capacidad. Cada tamaño cuenta con variantes base (sin entrenamiento de instrucciones), instruct (optimizado para seguimiento de comandos) y visión-lenguaje (con capacidad de procesamiento de imágenes). El modelo de 8B alcanza una mejora de rendimiento de 6× en tokens por paso comparado con Qwen3-8B en condiciones equivalentes, una ganancia significativa para aplicaciones industriales.
Problema de los decodificadores autorregresivos tradicionales
Los modelos de lenguaje convencionales utilizan decodificación autorregresiova, generando un token a la vez de manera secuencial. Este enfoque, aunque preciso, crea un cuello de botella severo: cada token depende del anterior, limitando el paralelismo de cómputo. En escenarios de producción—especialmente en plantas de manufactura que requieren respuestas rápidas para diagnóstico de anomalías o control de procesos—esta latencia es problemática. Nemotron-Labs-Diffusion aborda este limitante ofreciendo modos alternativos que generan múltiples tokens en paralelo durante un único paso forward.
Cómo funcionan los tres modos
El modo autorregresiovo mantiene compatibilidad con inferencia estándar y máxima calidad para tareas donde la precisión es crítica. La decodificación basada en difusión reorganiza el proceso generativo como un problema de refinamiento iterativo, permitiendo generar candidatos de múltiples tokens simultáneamente y refinarlos en paralelo. La decodificación especulativa, por su parte, predice especulativamente varios tokens futuros usando un modelo más ligero y valida su corrección contra el modelo completo, ganando velocidad sin sacrificar coherencia.
Implicaciones para la industria latinoamericana
En contextos de manufactura y automatización industrial en Latinoamérica, donde la infraestructura de cómputo no siempre es de última generación, un modelo que reduce la latencia de inferencia en 6× tiene implicaciones concretas: reducción de costos de operación en GPU, mejor aprovechamiento de hardware existente, y viabilidad de desplegar LLMs en controladores edge y sistemas MES con restricciones de poder computacional. Aplicaciones como análisis predictivo de fallas, optimización de secuencias de producción, o interpretación de datos de sensores en tiempo real se vuelven más accesibles para empresas que enfrentan limitaciones presupuestarias. La disponibilidad de variantes pequeñas (3B) es especialmente relevante para el edge industrial, donde modelos más compactos pero eficientes permiten tomar decisiones autónomas sin depender constantemente de servidores centralizados.
Este resumen es un análisis original. Para leer la noticia completa visita la fuente original: MarkTechPost →
Sigue leyendo
Nemotron-Labs: Generación de texto a velocidad de luz con modelos de difusión
NVIDIA presenta Nemotron-Labs Diffusion, una arquitectura innovadora que acelera significativamente la generación de texto mediante modelos de difusión. La tecnología promete reducir latencias en aplicaciones de IA generativa para infraestructuras industriales y empresariales.
Fuente: Hugging Face Blog
NVIDIA presenta metodología de entrenamiento a 4 bits con NVFP4
NVIDIA desarrolla un nuevo formato de precisión reducida llamado NVFP4 que permite entrenar modelos de lenguaje grandes a solo 4 bits, validado exitosamente en un modelo híbrido de 12 mil millones de parámetros con 10 billones de tokens, manteniendo precisión comparable a formatos de mayor precisión
Fuente: MarkTechPost
Desvelando el razonamiento interno de los modelos IA
Anthropic descubre nuevas formas de acceder a los procesos de razonamiento interno de Claude, abriendo perspectivas sobre cómo estos modelos generativos construyen respuestas. El hallazgo tiene implicaciones para la transparencia y confiabilidad de sistemas IA en aplicaciones críticas.
Fuente: MIT Technology Review
NVIDIA lanza Audex: modelo multimodal audio-texto unificado
NVIDIA presenta Audex (Nemotron-Labs-Audex-30B-A3B), un modelo de lenguaje que integra comprensión de audio, reconocimiento de voz, traducción, síntesis de voz y generación de audio en una única arquitectura MoE, preservando la inteligencia textual de su backbone Nemotron-Cascade-2.
Fuente: MarkTechPost
Etched desafía a Nvidia con valoración de $5B y $1B en ventas de chips IA
La startup Etched, competidora directa de Nvidia, alcanza una valuación de $5 mil millones tras asegurar $1 mil millón en contratos para sus sistemas de inferencia de IA. El hito refleja la creciente demanda de alternativas especializadas en procesamiento de inteligencia artificial.
Fuente: TechCrunch AI
Startups asiáticas lanzan modelos de IA rivales ante restricciones de exportación estadounidenses
Empresas emergentes en Asia desarrollan modelos de lenguaje con capacidades competitivas, aprovechando las restricciones que EE.UU. impone a laboratorios como Anthropic. Esta tendencia podría reconfigurar el mercado global de IA generativa.
Fuente: TechCrunch AI