StepFun presenta StepAudio 2.5: modelo de voz en tiempo real con personalización de rol
Por Redacción Automatización LatAm · 24 de mayo de 2026 · Fuente original: MarkTechPost
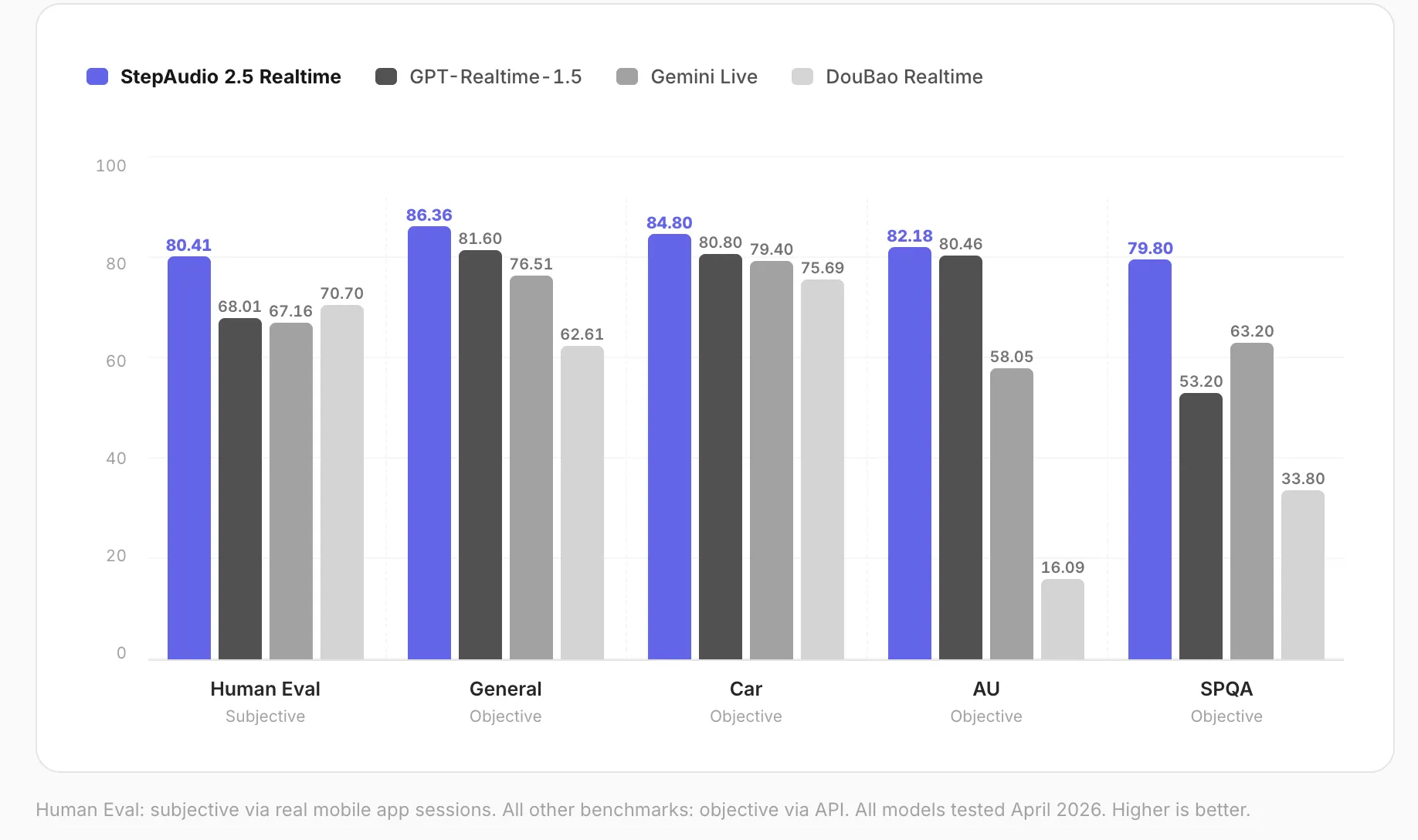
StepFun lanzó StepAudio 2.5 Realtime, un modelo de lenguaje de voz end-to-end con capacidades de personalización de personaje y comprensión paralinguística. El sistema soporta chino e inglés, integración vía WebSocket y obtuvo puntuaciones líderes en evaluaciones de desempeño.
Contexto: Evolución de modelos de voz empresariales
Los modelos de lenguaje de voz (speech LLMs) se han convertido en componentes clave para sistemas de interacción humano-máquina en entornos industriales. StepFun, laboratorio de IA con sede en Shanghái, ha consolidado su posición en este espacio con iteraciones sucesivas de su plataforma StepAudio, dirigidas a aplicaciones que requieren respuestas en tiempo real con características de personalización avanzada.
El lanzamiento: StepAudio 2.5 Realtime
En mayo de 2026, StepFun presentó StepAudio 2.5 Realtime, una solución end-to-end que integra procesamiento de voz, generación de lenguaje y síntesis de audio en un único flujo. El sistema opera mediante conexiones WebSocket, facilitando la integración en aplicaciones web y plataformas de control remoto. Soporta tanto chino mandarín como inglés, lo que posibilita su despliegue en contextos multilingües.
Un aspecto diferenciador es la capacidad de personalización de rol (roleplay-specific RLHF), que permite ajustar el comportamiento y tono del modelo mediante aprendizaje por refuerzo a partir de retroalimentación humana. Esta característica responde a casos de uso donde el asistente requiere adoptar perfiles específicos: desde técnicos de mantenimiento hasta agentes de atención a clientes con personalidades definidas.
Desempeño técnico y comprensión paralinguística
El modelo fue evaluado en abril de 2026 mediante cinco dimensiones de benchmark. StepAudio 2.5 Realtime alcanzó la primera posición en todas ellas, destacando un puntaje de evaluación humana de 80.41 puntos (en escala de 100) y 82.18 en comprensión paralinguística.
La comprensión paralinguística refiere a la capacidad de detectar e interpretar elementos no verbales en el habla: énfasis emocional, entonación, velocidad de locución, pausas y otros indicadores que transmiten información más allá del contenido literal de las palabras. En contextos industriales, esto es relevante para sistemas que deben reconocer alertas verbales, frustración en operadores o cambios en el tono que señalen anomalías.
Implicaciones para aplicaciones en América Latina
En plantas manufactureras latinoamericanas, un modelo de voz multilingüe con estas capacidades habilita casos de uso concretos:
- Asistentes de control de procesos: operadores pueden dictar comandos a sistemas SCADA o HMI con reconocimiento de intención robusta, incluso en ambientes ruidosos.
- Capacitación y simulación: entrenamientos en tiempo real donde el modelo asume roles de supervisor, técnico o cliente para ejercicios de resolución de problemas.
- Monitoreo de plantas: integración con sistemas de vigilancia que interpreten reportes verbales de anomalías, considerando el estado emocional del operador.
La API WebSocket simplifica la integración con infraestructuras existentes de IT/OT, aunque requiere evaluación de seguridad OT conforme a normas como IEC 62443 antes de desplegar en entornos críticos.
Perspectiva de mercado
El lanzamiento de StepAudio 2.5 Realtime posiciona a StepFun como competidor relevante frente a proveedores occidentales en el segmento de speech LLMs empresariales. La capacidad de personalización de rol y el soporte nativo a chino abren mercados en Asia-Pacífico, mientras que la adición de inglés facilita expansión global. Para operadores en Latinoamérica, esto significa mayor disponibilidad de soluciones localizadas sin dependencia exclusiva de proveedores estadounidenses o europeos.
Este resumen es un análisis original. Para leer la noticia completa visita la fuente original: MarkTechPost →
Sigue leyendo
Desvelando el razonamiento interno de los modelos IA
Anthropic descubre nuevas formas de acceder a los procesos de razonamiento interno de Claude, abriendo perspectivas sobre cómo estos modelos generativos construyen respuestas. El hallazgo tiene implicaciones para la transparencia y confiabilidad de sistemas IA en aplicaciones críticas.
Fuente: MIT Technology Review
Meta inicia producción de chips IA propios en septiembre
Meta acelerará la fabricación de sus procesadores de inteligencia artificial personalizados a partir de septiembre, reduciendo su dependencia de proveedores externos como Nvidia y disminuyendo costos operativos.
Fuente: TechCrunch AI
Venice AI alcanza estatus de unicornio con $65M en Serie A
La plataforma de IA Venice AI logra valuación de mil millones de dólares impulsada por su enfoque de privacidad y un flujo de ingresos anualizados superior a $70 millones, consolidándose como modelo rentable en el ecosistema de IA generativa.
Fuente: TechCrunch AI
IA en agricultura: oportunidad sin datos listos
La inteligencia artificial promete transformar la agricultura, pero expertos advierten que la industria debe preparar su infraestructura de datos antes de invertir. Sin bases sólidas, los proyectos de IA fracasan sin importar el potencial técnico.
Fuente: MIT Technology Review
IA Agentiva: qué es hoy y hacia dónde debería evolucionar
Un investigador del MIT analiza el funcionamiento real de los agentes de IA más allá del marketing, explorando sus capacidades actuales y el potencial transformador para la automatización industrial en los próximos años.
Fuente: MIT News — AI
Administración Trump autoriza uso de modelo IA Mythos en más de 100 organizaciones estadounidenses
La administración Trump ha autorizado el acceso a Mythos 5, un modelo de IA de Anthropic, para más de 100 empresas y agencias gubernamentales estadounidenses, incluyendo a sus empleados no estadounidenses.
Fuente: TechCrunch AI