Together AI libera OSCAR: cuantización de caché KV de 2 bits para LLMs de contexto largo
Por Redacción Automatización LatAm · 25 de mayo de 2026 · Fuente original: MarkTechPost
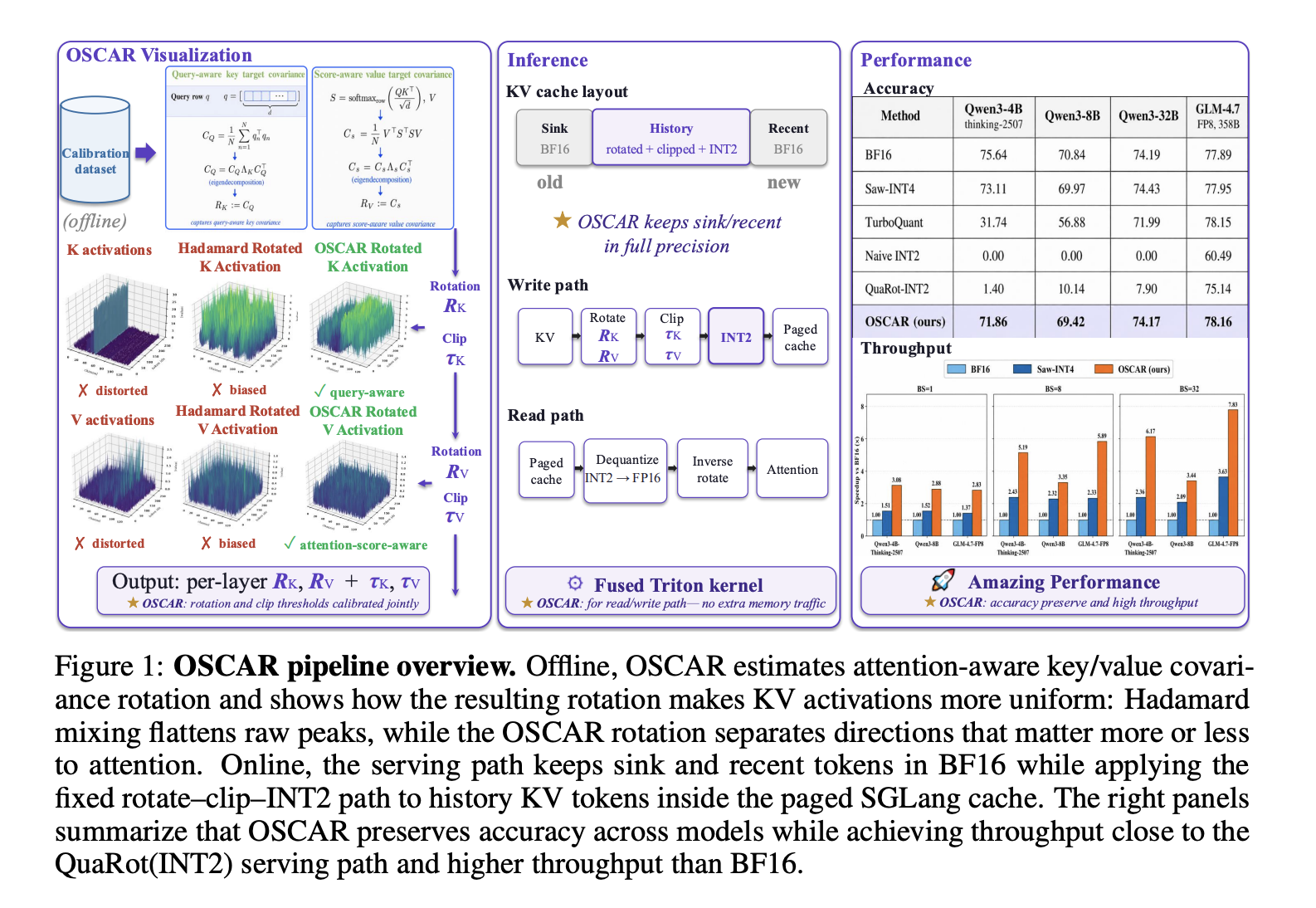
Together AI ha abierto el código de OSCAR, un sistema de cuantización INT2 para caché de pares clave-valor (KV) que optimiza el servicio de LLMs con contextos extensos. El método logra reducir memoria en 8× y acelerar decodificación hasta 3× manteniendo precisión cercana a modelos sin comprimir.
Contexto: El desafío de servir LLMs largos
Los modelos de lenguaje de gran escala enfrentan un cuello de botella fundamental cuando procesan secuencias extensas: el caché de pares clave-valor (KV cache) crece linealmente con la longitud del contexto. En aplicaciones reales—documentos legales, historiales de conversación prolongados, análisis de código—esta memoria se vuelve prohibitiva. Una estrategia común es comprimir mediante cuantización, pero los métodos convencionales pierden precisión rápidamente.
OSCAR: Rotación consciente de la atención
OSCAR (Offline Spectral Covariance-Aware Rotation) representa un avance cualitativo. A diferencia de enfoques previos que aplican transformaciones Hadamard genéricas sin considerar los datos reales, OSCAR estima estructuras de covarianza específicas de la atención durante una fase offline y deriva rotaciones personalizadas para claves y valores por separado.
El sistema comprime a 2.28 bits por elemento KV (INT2 cuantizado), logrando una reducción de memoria de aproximadamente 8× respecto a precisión BF16 estándar. En las pruebas con Qwen3-4B-Thinking-2507, la brecha de precisión se reduce a solo 3.78 puntos porcentuales; en Qwen3-8B, apenas 1.42 puntos.
Rendimiento y escalabilidad
El beneficio más evidente está en la velocidad de decodificación: a longitudes de contexto de 100K tokens, OSCAR alcanza aceleración de hasta 3×. Esta mejora es fundamental para aplicaciones interactivas donde la latencia determina la experiencia del usuario.
La cuantización consciente de la atención es técnicamente elegante: en lugar de comprimir uniformemente, OSCAR identifica qué partes del caché KV son más sensibles a cambios (según patrones de atención) y asigna bits diferencialmente. Las claves y valores que participan en atención crítica reciben tratamiento más cuidadoso, mientras que elementos menos relevantes se pueden comprimir más agresivamente.
Implicaciones para Latinoamérica
En la región, donde muchos centros de datos operan con presupuestos ajustados y hardware heterogéneo, técnicas como OSCAR son transformadoras. Organizaciones que no pueden costear clusters masivos de GPU H100 pueden ahora ejecutar modelos Qwen de capacidad significativa con contexto extendido en servidores de generación anterior.
Además, la liberación del código por parte de Together AI democratiza el acceso a esta tecnología. Investigadores y equipos de IA en universidades y startups latinoamericanas pueden integrar OSCAR en pipelines propios sin depender de soluciones propietarias.
Direcciones futuras
El método sienta base para exploración adicional: aplicar esquemas de cuantización jerárquicos, investigar quantization-aware training (QAT) para mejorar convergencia post-compresión, y adaptar OSCAR a modelos multimodales con caché KV en múltiples modalidades.
Para equipos de operaciones de IA (MLOps) e infraestructura, OSCAR es una herramienta inmediata para optimizar costos sin sacrificar capacidad funcional en producción.
Este resumen es un análisis original. Para leer la noticia completa visita la fuente original: MarkTechPost →
Sigue leyendo
Compresión y evaluación de LLMs con cuantización FP8, GPTQ y SmoothQuant
Un tutorial práctico demuestra técnicas de cuantización post-entrenamiento para reducir el tamaño y latencia de modelos de lenguaje ajustados con instrucciones, comparando estrategias de compresión y su impacto en rendimiento.
Fuente: MarkTechPost
Desvelan el funcionamiento interno de Claude y estrategia de OpenAI
Anthropic logró identificar estructuras ocultas dentro de Claude que revelan cómo el modelo procesa conceptos complejos. Simultáneamente, OpenAI avanza en su estrategia de plataforma integrada.
Fuente: MIT Technology Review
Documentación de planta: la barrera silenciosa para agentes IA
Los sistemas de IA en manufactura enfrentan un obstáculo crítico: la información operativa está atrapada en formatos heredados no estructurados, diseñados para humanos, no para máquinas. Expertos exploran cómo superar esta brecha en AI Manufacturing Day 2026.
Fuente: IIoT World
Cadetes sin experiencia crean apps IA para defensa con ChatGPT
Investigadores del MIT y la Fuerza Aérea estadounidense demostraron que chatbots de IA permiten a militares sin formación técnica desarrollar aplicaciones de software viables adaptadas a sus necesidades operacionales específicas.
Fuente: MIT News — AI
NVIDIA Horizon: Agente IA autonomo para diseño RTL
NVIDIA presenta Horizon, un agente de IA que automatiza el diseño de circuitos RTL mediante repositorios versionados, alcanzando 100% de finalización en benchmarks estándar del sector.
Fuente: MarkTechPost
Microsoft crea división de despliegue de IA con inversión de $2.5B
Microsoft establece una unidad dedicada para implementar soluciones de IA en empresas, siguiendo la estrategia de rivales como Amazon, OpenAI y Anthropic. La inversión busca acelerar la adopción de modelos generativos en la industria.
Fuente: TechCrunch AI