MemPrivacy: Framework que protege datos en memorias en la nube sin perder utilidad
Por Redacción Automatización LatAm · 18 de mayo de 2026 · Fuente original: MarkTechPost
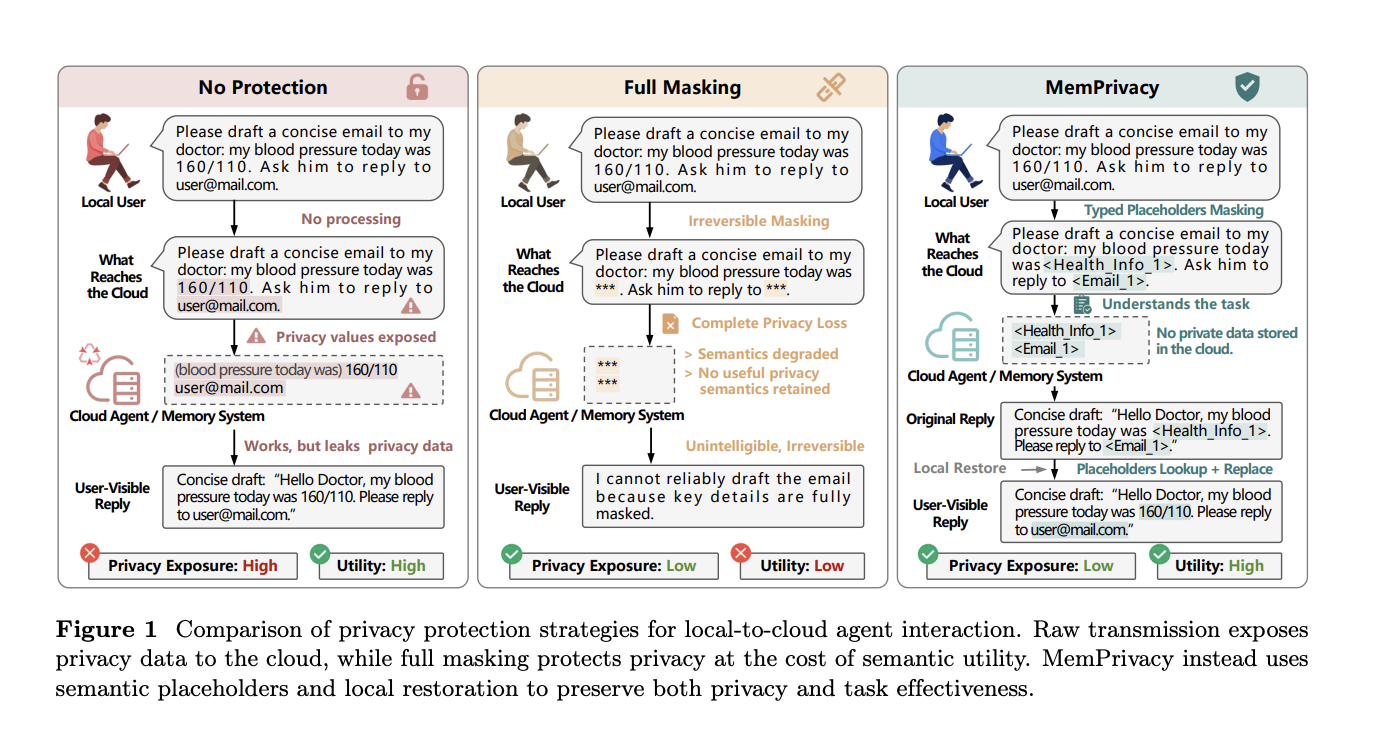
Un nuevo framework desarrollado por investigadores chinos combina procesamiento en edge con pseudonimización reversible local para proteger información sensible en sistemas de memoria distribuida, manteniendo la funcionalidad de agentes basados en LLM en producción.
El dilema de la memoria útil versus privacidad
La adopción acelerada de agentes inteligentes basados en modelos de lenguaje grande presenta un desafío fundamental para desarrolladores y empresas: los sistemas de memoria en la nube que hacen que estos agentes sean verdaderamente útiles requieren almacenar información detallada sobre usuarios, interacciones y contexto histórico. Cuanta mayor riqueza de datos históricos disponible, más potentes y personalizados son los sistemas. Sin embargo, esta misma capacidad expone datos privados a riesgos de fuga, acceso no autorizado y usos secundarios no previstos.
Introducción a MemPrivacy
Investigadores de MemTensor (con sede en Shanghai), HONOR Device y la Universidad de Tongji han presentado MemPrivacy, un framework arquitectónico que resuelve esta tensión mediante pseudonimización reversible ejecutada localmente en dispositivos edge. La solución separa físicamente la responsabilidad de mantener datos sensibles del almacenamiento centralizado en la nube, permitiendo que los agentes inteligentes aprovechen memorias distribuidas sin exponer identidades ni información personal de forma permanente.
Mecanismo técnico y operación
El corazón del framework es la pseudonimización reversible local: datos confidenciales como nombres, identificadores únicos, conversaciones personales o históricos de comportamiento se transforman en tokens opacos en el dispositivo del usuario antes de ser enviados a servidores en la nube. Estos tokens mantienen relaciones lógicas que permiten a los LLMs entender contexto y patrones sin acceso directo a los datos originales. Solo el dispositivo edge conserva las claves de reversión, lo que significa que incluso si un servidor en la nube es comprometido, los atacantes obtienen datos desanonimizados inútiles sin significado.
Esta arquitectura es particularmente relevante para sistemas que requieren memoria persistente y contextual: chatbots empresariales, asistentes virtuales personalizados, y plataformas de recomendación que necesitan recordar preferencias y patrones de un usuario sin exposición innecesaria.
Implicaciones para la industria en América Latina
En mercados como México, Brasil y Colombia, donde el cumplimiento regulatorio es cada vez más exigente, esta aproximación ofrece un camino para empresas que desean desplegar sistemas de IA en la nube sin infringir leyes de protección de datos. Operadores de telecomunicaciones, plataformas fintech y servicios de atención al cliente pueden mantener memoria útil de interacciones mientras garantizan que los datos permanecen bajo control del usuario.
El framework también reduce la carga de auditoría y cumplimiento: al mantener datos sensibles cifrados y localmente procesados, las organizaciones reducen su superficie de ataque y pueden demostrar más fácilmente conformidad con estándares como ISO 27001 y regulaciones locales.
Consideraciones técnicas futuras
Los desafíos restantes incluyen la latencia de reversión en escenarios de miles de usuarios concurrentes, la escalabilidad del almacenamiento de claves criptográficas en dispositivos heterogéneos, y la integración fluida con infraestructuras existentes de edge computing. El equipo continúa refinando el balance entre seguridad, rendimiento y usabilidad.
Este resumen es un análisis original. Para leer la noticia completa visita la fuente original: MarkTechPost →
Sigue leyendo
Google lanza LiteRT.js para ejecutar modelos de IA en navegadores web
Google presentó LiteRT.js, una interfaz JavaScript que permite ejecutar modelos de aprendizaje automático directamente en navegadores web con aceleración GPU. La herramienta ofrece mejoras de velocidad de hasta 3x respecto a otros runtimes web, y hasta 60x en procesadores gráficos.
Fuente: MarkTechPost
Métodos de IA para decisiones en tiempo real con recursos limitados
Investigadores del MIT desarrollan técnicas que permiten a modelos de IA tomar decisiones continuas usando recursos computacionales restringidos, abriendo aplicaciones en plantas y sistemas de control industrial.
Fuente: MIT News — AI
Sistemas de IA Multiagente Colaborativos en Manufactura
Fabricantes líderes avanzan hacia sistemas de IA multiagente donde agentes especializados colaboran directamente, dejando atrás asistentes de IA simples. ABB define una hoja de ruta hacia operaciones autónomas con seis niveles de sofisticación.
Fuente: IIoT World
Memoria ferroeléctrica y diseño de chips IA dominan la actualidad tecnológica
Los temas más relevantes en electrónica incluyen avances en memoria ferroeléctrica, financiamiento para diseño personalizado de chips IA y desarrollos en equipos de metrología. Estos campos impulsan la innovación en procesamiento de datos y fabricación de semiconductores.
Fuente: Electronics Weekly
Liquid AI lanza LFM2.5: modelo MoE eficiente para dispositivos locales
Liquid AI presenta un modelo de lenguaje optimizado con arquitectura Mixture of Experts que activa solo 1.5B de 8.3B parámetros totales, permitiendo ejecución en hardware de consumo con ventana de contexto de 128K tokens y capacidades de razonamiento.
Fuente: MarkTechPost
IA reconstruye voces de pilotos fallecidos en grabaciones de cabina
Investigadores utilizaron modelos de inteligencia artificial para reconstruir grabaciones de voz a partir de espectrogramas de registros de cabina, lo que obligó a la NTSB a restringir temporalmente el acceso a su sistema de archivos.
Fuente: TechCrunch AI